
Rahul Hemrajani
December 30, 2024
Can Large Language Model Chatbots Provide Effective Legal Advice? Part 3: Retrieval-Augmented Generation and Fine-tuning
This is the third post in the GenAI and Consumer Law series. You can read the first post here, and the second, here. This series brings you insights from an ongoing research project that explores the potential of large language models (LLMs) in enhancing India’s consumer grievance redressal system. Hear from the NLSIU research team as they navigate the possibilities and challenges of using LLMs to build public solutions and augment transformative legal reforms in India. Read more about the project here.
The last two posts in this series examined the current capabilities of LLMs in providing legal advice and explored how techniques like prompt engineering can enhance their effectiveness. In this post, I discuss two additional techniques—retrieval-augmented generation and fine-tuning—and conclude the series with an important caveat.
Retrieval Augmented Generation
While prompt engineering can help improve the quality and specificity of legal advice provided by LLM chatbots, the effectiveness of LLMs is ultimately constrained by the completeness and accuracy of the chatbot’s knowledge base. Even the most well-crafted prompts cannot elicit information that the chatbot does not have access to or has not been trained on.
This limitation is particularly evident when it comes to jurisdiction specific legal information and procedures. Although ChatGPT and other LLM chatbots have extensive knowledge bases, they may still lack the depth and granularity required to provide comprehensive advice on complex legal matters, especially in the context of Indian law. For instance, when asked about the e-Daakhil procedure for filing consumer complaints in India, ChatGPT 4 may not be able to provide specific details about the documents required or the proper format for drafting a complaint that aligns with the norms followed by Indian consumer courts. Similarly, the chatbot may not have access to the latest rules and notifications under the Consumer Protection Act (CPA), which could lead to incomplete or outdated advice. Moreover, the context window for prompts is limited, which means that there is a cap on the length of both queries and responses. For ChatGPT 4, this context window is approximately 8,000 tokens, or 6,000 words, which may not capture all the nuances and variations of legal queries.
To overcome the limitations of static knowledge bases and rule-based prompts, researchers and developers are turning to Retrieval Augmented Generation (RAG) models. RAG is a hybrid approach that combines the strengths of retrieval-based models—which search for relevant information from a large corpus of documents—and generative models—which use this information to create coherent and contextually appropriate responses.
In a RAG model, when the chatbot receives a query, it first searches through a vast knowledge corpus to find the most relevant documents or passages related to the query. These retrieved documents are then fed into the chatbot’s generative model, which uses them to generate a response that is informed by the most up-to-date and context-specific legal information available.
A RAG model typically has two main components:
- Retriever: This component retrieves relevant documents or pieces of information from a predefined corpus based on the input query.
- Generator: This component, typically a generative language model like GPT, uses the retrieved information to generate a coherent and contextually appropriate response.
The RAG approach has several advantages over traditional LLM chatbots. First, it allows the chatbot to access a much larger and more diverse knowledge base, as the retrieval step can search through vast repositories of legal documents, case law, and other relevant sources. Second, it ensures that the chatbot’s responses are grounded in the most current and accurate legal information, as the retrieval step can be repeated for each new query, pulling in the latest updates and amendments to the law.
One powerful way to implement the RAG approach for legal advice chatbots is through the use of Open AI’s Custom GPT. This platform allows users to upload one or multiple documents to serve as the knowledge base for the chatbot. When a user asks a question, the Custom GPT model searches through this knowledge base, retrieves the most relevant information, and incorporates it into the generated response.
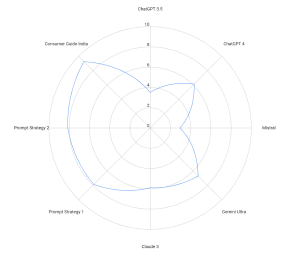
To test this approach in the context of Indian consumer law, our research team created a Custom GPT model called Consumer Guide India. We provided the model with a curated knowledge base consisting of FAQs on consumer grievances issued by the Department of Consumer Affairs, along with other relevant legal documents and sources. We also included a system prompt—read more about system prompts here—to prime the chatbot to provide specific advice and information related to consumer law in India.
When we ran the airline grievance query through our Consumer Guide India model, the results were impressive. The chatbot was able to provide precise information about the AirSewa portal, consumer helplines, and the process for filing a complaint with the relevant District Consumer Redressal Commission. It also suggested using the e-Daakhil portal for e-filing and, when prompted, was able to generate accurate complaint drafts.
The effectiveness of this approach was reflected in the evaluations conducted by our student testers. As Figure 1 shows, Consumer Guide India received an average score of 9.26, surpassing the scores achieved even with our best, most well-crafted prompts. This demonstrates the power of combining RAG with custom knowledge bases and system prompts tailored to specific legal domains and jurisdictions.
Fine-Tuning
Clients do not always know—or know how to articulate—what they need. Part of a lawyer’s job is to gather relevant information through a series of targeted questions, steering the conversation to better assess their requirements before offering them possible recourses. Even the best trained chatbots cannot offer the conversational flow and context awareness of a skilled human lawyer. While RAG can enhance the chatbot’s ability to fetch and use information dynamically, fine-tuning ensures that the chatbot maintains a consistent tone, style and approach, which is crucial for user experience and brand alignment. Fine-tuning involves training LLMs on specialised legal datasets that reflect the specific laws and regulations of different jurisdictions. By exposing the models to high-quality, representative legal texts, we can enhance their ability to provide accurate and context-specific advice. This process can be further refined by incorporating feedback from legal professionals and real-world use cases. For example, Harvey, a model trained by OpenAI on legal texts, achieved ‘a 35% increase in conversation summarization quality, a 33% increase in intent recognition accuracy, and an increase in satisfaction scores from 3.6 to 4.5 (out of 5) when comparing the fine-tuned model to GPT-4.’
One method of fine-tuning the model is to train it on synthetic conversations on consumer grievance redressal between a hypothetical lawyer and a consumer. This process involves scripting dialogues that mimic real-world interactions between consumers and legal advisors. These synthetic conversations are crafted to cover a wide range of consumer law issues, ensuring comprehensive coverage of potential queries. Tools like OpenAI’s GPT-4, in combination with data augmentation platforms such as Snorkel or TARS, can be used to generate and curate these synthetic datasets. Experts can then manually edit them to ensure compliance with law and format.
Unlike RAG models, however, there is no easy, user-facing interface that can be immediately deployed to answer queries. One has to use the Application Programming Interface (API) of an LLM model, and a fine-tuning library (such as LLAMAindex or Langchain) to create the fine-tuned model. One process you can follow, for example, is to load your pre-trained model (e.g., GPT-4) into the Hugging Face Transformers framework. Use your indexed dataset to create a training script, specifying parameters like learning rate and batch size. Run the fine-tuning process by training the model on your dataset, allowing it to learn from the synthetic conversations. After fine-tuning, validate the model’s performance with test data to ensure it provides accurate and context-specific legal advice. This process should, in principle, enhance the model’s ability to handle consumer law queries.
While fine-tuning offers significant benefits, it is more expensive and time-consuming than prompt engineering and RAG models. Its success largely depends on the quality and quantity of the synthetic dataset used. A larger, more diverse and accurate dataset of synthetic conversations will yield a better-performing model, but creating such a dataset can be resource-intensive and requires specialised hardware and significant technical expertise. Additionally, fine-tuning is an iterative process that may require multiple rounds of training, evaluation, and adjustment to achieve optimal results.
Conclusion
The idea of accessible, affordable, and instant legal assistance through AI chatbots is undeniably appealing, particularly in a country like India where many lack the means to hire a lawyer. As technology continues to advance, it is crucial to address challenges of data quality, bias and reliability in LLM chatbots. Techniques such as prompt engineering, retrieval-augmented generation, fine-tuning, and human-in-the-loop approaches offer potential avenues for improvement.
By carefully considering the trade-offs and combining these approaches in a strategic manner, developers can create AI-powered legal advice chatbots that are not only technologically advanced but also deeply attuned to the unique needs and challenges of legal practice in different jurisdictions. This is what we are trying to do as we build our own consumer grievances chatbot under the GenAI and Consumer Law project at NLSIU.
Before I conclude, a caveat is in order. While chatbots can be programmed to provide useful responses, they still lack the empathy and emotional intelligence of human lawyers. Legal issues often involve sensitive and stressful situations. Clients need not just legal advice but also emotional support and understanding. Chatbots, even with fine-tuning, may struggle to provide the level of empathy and human connection that is often crucial in legal services.
Our eventual goal should be to harness the power of AI to make legal advice and assistance more accessible, affordable and effective for everyone, while also recognising the enduring importance of human judgement, context awareness, and compassion in the practice of law. By striking the right balance between technological innovation and human expertise, we can create a future in which AI chatbots and human lawyers work together seamlessly to provide the best possible legal services to those who need them most.
About the Author
Dr. Rahul Hemrajani is Assistant Professor of Law at NLSIU, Bengaluru. He is part of the research team for the Project on Consumer Law with Meta, IIT-B & the Department of Consumer Affairs.